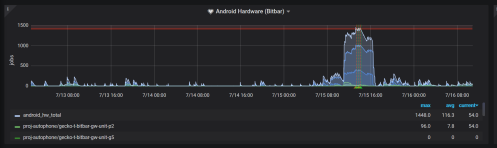
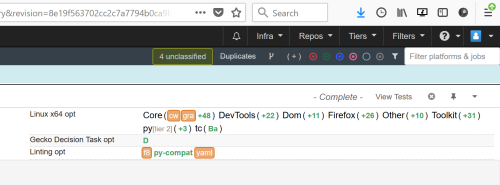
Whenever a patch is landed on autoland, it will run many builds and tests to make sure there are no regressions. Unfortunately many times we find a regression and 99% of the time backout the changes so they can be fixed. This work is done by the Sheriff team at Mozilla- they monitor the trees and when something is wrong, they work to fix it (sometimes by a quick fix, usually by a backout). A quick fact, there were 1228 regressions in H1 (January-June) 2019.
My goal in writing is not to recommend change, but instead to start conversations and figure out what data we should be collecting in order to have data driven discussions. Only then would I expect that recommendations for changes would come forth.
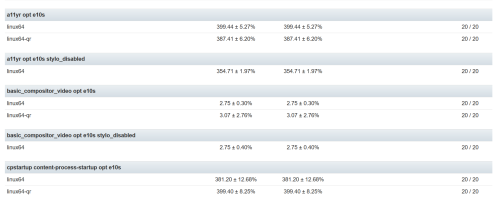
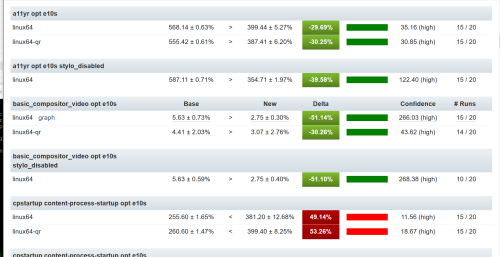
What got me started in looking at regressions was trying to answer a question: “How many regressions did X catch?” This alone is a tough question, instead I think the question should be “If we were not running X, how many regressions would our end users see?” This is a much different question and has two distinct parts:
- Unique Regressions: Only look at regressions found that only X found, not found on both X and Y
- Product Fixes: did the regression result in changing code that we ship to users? (i.e. not editing the test)
- Final Fix: many times a patch [set] lands and is backed out multiple times, in this case do we look at each time it was backed out, or only the change from initial landing to final landing?
These can be more difficult to answer. For example, Product Fixes- maybe by editing the test case we are preventing a regression in the future because the test is more accurate.
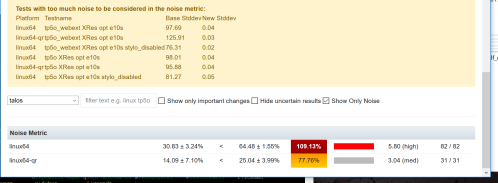
In addition we need to understand how accurate the data we are using is. As the sheriffs do a great job, they are human and humans make judgement calls. In this case once a job is marked as “fixed_by_commit”, then we cannot go back in and edit it, so a typo or bad data will result in incorrect data. To add to it, often times multiple patches are backed out at the same time, so is it correct to say that changes from bug A and bug B should be considered?
This year I have looked at this data many times to answer:
- how many unique regressions did linux32 catch?
- how many unique regressions did opt tests catch vs pgo?
- how many regressions did web-platform-tests catch?
- In H1 – 90 regressions, 17 product changes
This data is important to harvest because if we were to turn off a set of jobs or run them as tier-2 we would end up missing regressions. But if all we miss is editing manifests to disable failing tests, then we are getting no value from the test jobs- so it is important to look at what the regression outcome was.
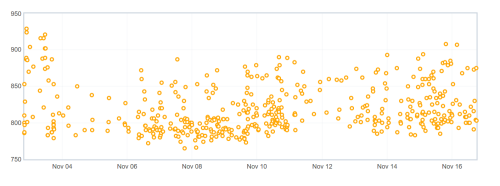
In fact every time I did this I would run an active-data-recipe (fbc recipe in my repo) and have a large pile of data I needed to sort through and manually check. I spent some time every day for a few weeks looking at regressions and now I have looked at 700 (bugs/changesets). I found that in manually checking regressions, the end results fell into buckets:
| test | 196 | 28.00% |
| product | 272 | 38.86% |
| manifest | 134 | 19.14% |
| unknown | 48 | 6.86% |
| backout | 27 | 3.86% |
| infra | 23 | 3.29% |
Keep in mind that many of the changes which end up in mozilla-central are not only product bugs, but infrastructure bugs, test editing, etc.
After looking at many of these bugs, I found that ~80% of the time things are straightforward (single patch [set] landed, backed out once, relanded with clear comments). Data I would like to have easily available via a query:
- Files that are changed between backout and relanding (even if it is a new patch).
- A reason as part of phabricator that when we reland, it is required to have a few pre canned fields
Ideally this set of data would exist for not only backouts, but for anything that is landed to fix a regression (linting, build, manifest, typo).