
I gave an update 2 weeks ago on the current state of Stockwell (intermittent failures). I mentioned additional posts were coming and this is a second post in the series.
First off the tree sheriffs who maintain merges between branches, tree closures, backouts, hot fixes, and a many other actions that keep us releasing code do one important task, and that is star failures to a corresponding bug.
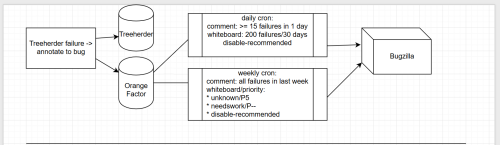
These annotations are saved in Treeherder and Orange Factor. Inside of Orange Factor, we have a robot that comments on bugs– this has been changing a bit more frequently this year to help meet our new triage needs.
Once we get bugs annotated, now we work on triaging them. Our primarily tool is Neglected Oranges which gives us a view of all failures that meet our threshold and don’t have a human comment in the last 7 days. Here is the next stage of the process:
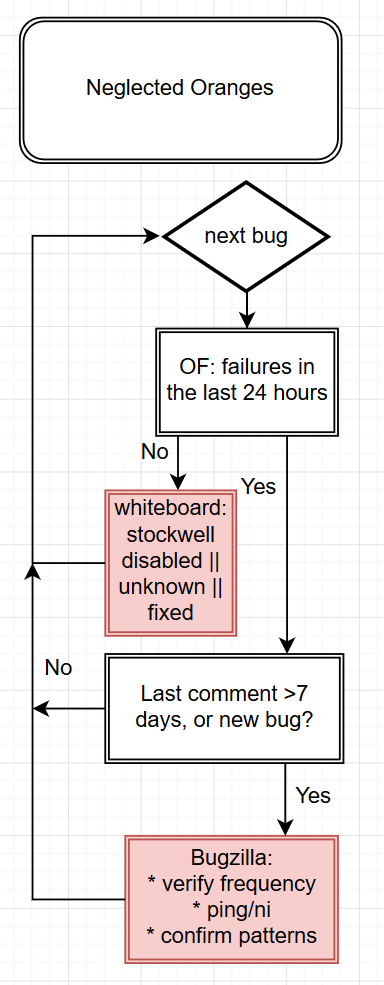
As you can see this is very simple, and it should be simple. The ideal state is adding more information to the bug which helps make it easier for the person we NI? to prioritize the bug and make a decision:
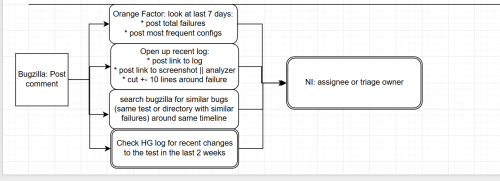
While there is a lot more we can do, and much more that we have done, this seems to be the most effective use when looking across 1000+ bugs that we have triaged so far this year.
In some cases a bug fails very frequently and there are no development resources to spend fixing the bug- these will sometimes cross our 200 failures in 30 days policy and will get a [stockwell disabled-recommended] whiteboard tag, we monitor this and work to disable bugs on a regular basis:
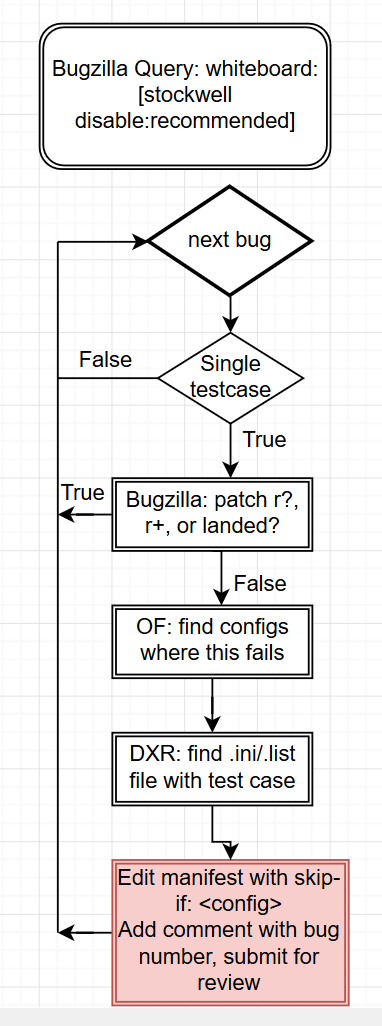
This isn’t as cut and dry as disable every bug, but we do disable as quickly as possible and push hard on the bugs that are not as trivial to disable.
There are many new people working on Intermittent Triage and having a clear understanding of what they are doing will help you know how a random bug ended up with a ni? to you!
