Here at Mozilla we run dozens of builds and hundreds of test jobs for every push to a tree. As time has gone on, we have gone from a couple hours from push to all tests complete to 4+ hours. With the exception of a few test jobs, we could complete our test results in
The question becomes, how do we manage to keep up test coverage without growing the number of machines? Right now we do this with buildbot coalescing (we queue up the jobs and skip the older ones when the load is high). While this works great, it causes us to skip a bunch of jobs (builds/tests) on random pushes and sometimes we need to go back in and manually schedule jobs to find failures. In fact, while keeping up with the automated alerts for talos regressions, the coalescing causes problems in over half of the regressions that I investigate!
Knowing that we live with coalescing and have for years, many of us started wondering if we need all of our tests. Ideally we could select tests that are statistically most significant to the changes being pushed, and if those pass, we could run the rest of the tests if there were available machines. To get there is tough, maybe there is a better way to solve this? Luckily we can mine meta data from treeherder (and the former tbpl) and determine which failures are intermittent and which have been fixed/caused by a different revision.
A few months ago we started looking into unique failures on the trees. Not just the failures, but which jobs failed. Normally when we have a failure detected by the automation, many jobs fail at once (for example: xpcshell tests will fail on all windows platforms, opt + debug). When you look at the common jobs which fail across all the failures over time, you can determine the minimum number of jobs required to detected all the failures. Keep in mind that we only need 1 job to represent a given failure.
As of today, we have data since August 13, 2014 (just shy of 180 days):
- 1061 failures caught by automation (for desktop builds/tests)
- 362 jobs are currently run for all desktop builds
- 285 jobs are optional and not needed to detect all 1061 regressions
To phrase this another way, we could have run 77 jobs per push and caught every regression in the last 6 months. Lets back up a bit and look at the regressions found- how many are there and how often do we see them:
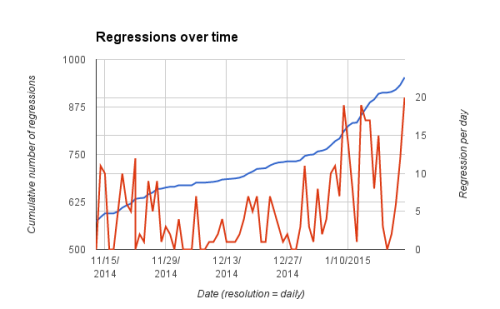
Cumulative and per day regressions
This is a lot of regressions, yay for automation. The problem is that this is historical data, not future data. Our tests, browser, and features change every day, this doesn’t seem very useful for predicting the future. This is a parallel to the stock market, there people invest in companies based on historical data and make decisions based on incoming data (press releases, quarterly earnings). This is the same concept. We have dozens of new failures every week, and if we only relied upon the 77 test jobs (which would catch all historical regressions) we would miss new ones. This is easy to detect, and we have mapped out the changes. Here it is on a calendar view (bold dates indicate a change was detected, i.e. a new job needed in the reduced set of jobs list):
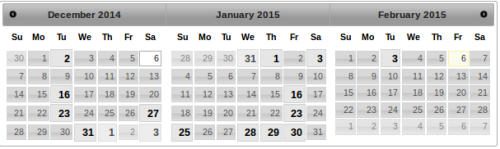 This translates to about 1.5 changes per week. To put this another way, if we were only running the 77 reduced set of jobs, we would have missed one regression December 2nd, and another December 16th, etc., or on average 1.5 regressions will be missed per week. In a scenario where we only ran the optional jobs once/hour on the integration branches, 1-2 times/week we would see a failure and have to backfill some jobs (as we currently do for coalesced jobs) for the last hour to find the push which caused the failure.
This translates to about 1.5 changes per week. To put this another way, if we were only running the 77 reduced set of jobs, we would have missed one regression December 2nd, and another December 16th, etc., or on average 1.5 regressions will be missed per week. In a scenario where we only ran the optional jobs once/hour on the integration branches, 1-2 times/week we would see a failure and have to backfill some jobs (as we currently do for coalesced jobs) for the last hour to find the push which caused the failure.
To put this into perspective, here is a similar view to what you would expect to see today on treeherder:
 For perspective, here is what it would look like assuming we only ran the reduced set of 77 jobs:
For perspective, here is what it would look like assuming we only ran the reduced set of 77 jobs:
 * keep in mind this is weighted such that we prefer to run jobs on linux* builds since those run in the cloud.
* keep in mind this is weighted such that we prefer to run jobs on linux* builds since those run in the cloud.
With all of this information, what do we plan to do with it? We plan to run the reduced set of jobs by default on all pushes, and use the [285] optional jobs as candidates for coalescing. Currently we force coalescing for debug unittests. This was done about 6 months ago because debug tests take considerably longer than opt, so if we could run them on every 2nd or 3rd build, we would save a lot of machine time. This is only being considered on integration trees that the sheriffs monitor (mozilla-inbound, fx-team).
Some questions that are commonly asked:
- How do you plan to keep this up to date?
- We run a cronjob every day and update our master list of jobs, failures, and optional jobs. This takes about 2 minutes.
- What are the chances the reduced set of jobs catch >1 failure? Do we need all 77 jobs?
- 77 jobs detect 1061 failures (100%)
- 35 jobs detect 977 failures (92%)
- 23 jobs detect 940 failures (88.6%)
- 12 jobs detect 900 failures (84.8%)
- How can we see the data:
- SETA website
- in the near future summary emails when we detect a *change* to mozilla.dev.tree-alerts
Thanks for reading so far! This project wouldn’t be here it it wasn’t for the many hours of work by Vaibhav, he continues to find more ways to contribute to Mozilla. If anything this should inspire you to think more about how our scheduling works and what great things we can do if we think out of the box.





