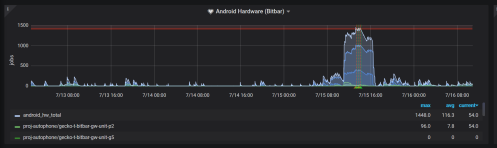
Last week it seemed that all our limited resource machines were perpetually backlogged. I wrote yesterday to provide insight into what we run and some of our limitations. This post will be discussing the Android phones backlog last week specifically.
The Android phones are hosted at Bitbar and we split them into pools (battery testing, unit testing, perf testing) with perf testing being the majority of the devices.
There were 6 fixes made which resulted in significant wins:
- Recovered offline devices at Bitbar
- Restarting host machines to fix intermittent connection issues at Bitbar
- Update Taskcluster generic-worker startup script to consume superceded jobs
- Rewrite the scheduling script as multi-threaded and utilize bitbar APIs more efficiently
- Turned off duplicate jobs that were on by accident last month
- Removed old taskcluster-worker devices
On top of this there are 3 future wins that could be done to help future proof this:
- upgrade android phones from 8.0 -> 9.0 for more stability
- Enable power testing on generic usb hubs rather than special hubs which require dedicated devices.
- merge all separate pools together to maximize device utilization
With the fixes in place, we are able to keep up with normal load and expect that future spikes in jobs will be shorter lived, instead of lasting an entire week.
Recovered offline devices at Bitbar
Every day a 2-5 devices are offline for some period of time. The Bitbar team finds some on their own and resets the devices, sometimes we notice them and ask for the devices
to be reset. In many cases the devices are hung or have trouble on a reboot (motivation for upgrading to 9.0). I will add to this that the week prior things started getting sideways and it was a holiday week for many, so less people were watching things and more devices ended up in various states.
In total we have 40 pixel2 devices in the perf pool (and 37 Motorola G5 devices as well) and 60 pixel2 devices when including the unittest and battery pools. We found that 19 devices were not accepting jobs and needed attention Monday July 8th. For planning purposes it is assumed that 10% of the devices will be offline, in this case we had 1/3 of our devices offline and we were doing merge day with a lot of big pushes running all the jobs.
Restarting host machines to fix intermittent connection issues at Bitbar
At Bitbar we have a host machine with 4 or more docker containers running and each docker container runs Linux with the Taskcluster generic-worker and the tools to run test jobs. Each docker container is also mapped directly to a phone. The host machines are rarely rebooted and maintained, and we noticed a few instances where the docker containers had trouble connecting to the network. A fix for this was to update the kernel and schedule periodic reboots.
Update Taskcluter generic-worker startup script
When the job is superseded, we would shut down the Taskcluster generic-worker, the docker image, and clean up. Previously it would terminate the job and docker container and then wait for another job to show up (often a 5-20 minute cycle). With the changes made Taskcluster generic-worker will just restart (not docker container) and quickly pick up the next job.
Rewrite the scheduling script as multi-threaded
This was a big area of improvement that was made. As our jobs increased in volume and had a wider range of runtimes, our tool for scheduling was iterating through the queue and devices and calling the APIs at Bitbar to spin up a worker and hand off a task. This is something that takes a few seconds per job or device and with 100 devices it could take 10+ minutes to come around and schedule a new job on a device. With changes made last week ( Bug 1563377 ) we now have jobs starting quickly <10 seconds, which greatly increases our device utilization.
Turn off duplicate opt jobs and only run PGO jobs
In reviewing what was run by default per push and on try, a big oversight was discovered. When we turned PGO on for Android, all the perf jobs were scheduled both for opt and PGO, when they should have been only scheduled for PGO. This was an easy fix and cut a large portion of the load down (Bug 1565644)
Removed old taskcluster-worker devices
Earlier this year we switched to Taskcluster generic-worker and in the transition had to split devices between the old taskcluster-worker and the new generic-worker (think of downstream branches). Now everything is run on generic-worker, but we had 4 devices still configured with taskcluster-worker sitting idle.
Given all of these changes, we will still have backlogs that on a bad day could take 12+ hours to schedule try tasks, but we feel confident with the current load we have that most of the time jobs will be started in a reasonable time window and worse case we will catch up every day.
A caveat to the last statement, we are enabling webrender reftests on android and this will increase the load by a couple devices/day. Any additional tests that we schedule or large series of try pushes will cause us to hit the tipping point. I suspect buying more devices will resolve many complaints about lag and backlogs. Waiting for 2 more weeks would be my recommendation to see if these changes made have a measurable change on our backlog. While we wait it would be good to have agreement on what is an acceptable backlog and when we cross that threshold regularly that we can quickly determine the number of devices needed to fix our problem.