
Last November we released Firefox v.57, otherwise known as Firefox Quantum. Quantum was in many ways a whole new browser with the focus on speed as compared to previous versions of Firefox.
As I write about many topics on my blog which are typically related to my current work at Mozilla, I haven’t written about measuring or monitoring Performance in a while. Now that we are almost a year out I thought it would be nice to look at a few of the key performance tests that were important for tracking in the Quantum release and what they look like today.
First I will look at the benchmark Speedometer which was used to track browser performance primarily of the JS engine and DOM. For this test, we measure the final score produced, so the higher the number the better:

You can see a large jump in April, that is when we upgraded the hardware we run the tests on, otherwise we have only improved since last year!
Next I want to look at our startup time test (ts_paint) which measure time to launch the browser from a command line in ms, in this case lower is better:
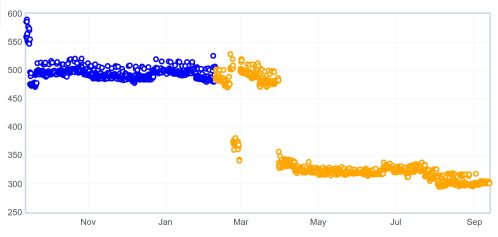
Here again, you can see the hardware upgrade in April, overall we have made this slightly better over the last year!
What is more interesting is a page load test. This is always an interesting test and there are many opinions about the right way to do this. How we do pageload is to record a page and replay it with mitmproxy. Lucky for us (thanks to neglect) we have not upgraded our pageset so we can really compare the same page load from last year to today.
For our pages we initially setup, we have 4 pages we recorded and have continued to test, all of these are measured in ms so lower is better.
Amazon.com (measuring time to first non blank paint):

We see our hardware upgrade in April, otherwise small improvements over the last year!
Facebook (logged in with a test user account, measuring time to first non blank paint):

Again, we have the hardware upgrade in April, and overall we have seen a few other improvements 🙂
Google (custom hero element on search results):

Here you can see that what we had a year ago, we were better, but a few ups and downs, overall we are not seeing gains, nor wins (and yes, the hardware upgrade is seen in April).
Youtube (measuring first non blank paint):
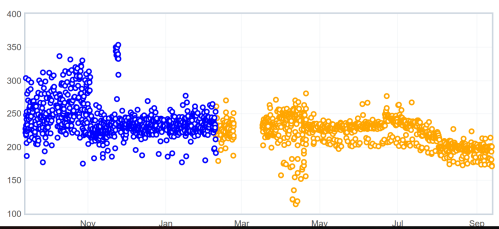
As you can see here, there wasn’t a big change in April with the hardware upgrade, but in the last 2 months we see some noticeable improvements!
In summary, none of our tests have shown regressions. Does this mean that Firefox v.63 (currently on Beta) is faster than Firefox Quantum release of last year? I think the graphs here show that is true, but your mileage may vary. It does help that we are testing the same tests (not changed) over time so we can really compare apples to apples. There have been changes in the browser and updates to tools to support other features including some browser preferences that change. We have found that we don’t necessarily measure real world experiences, but we get a good idea if we have made things significantly better or worse.
Some examples of how this might be different for you than what we measure in automation:
- We test in an isolated environment (custom prefs, fresh profile, no network to use, no other apps)
- Outdated pages that we load have most likely changed in the last year
- What we measure as a startup time or a page loaded time might not reflect what a user perceives as accurate
